This is why Boolean strings don’t work
In our previous posts we explored some of the challenges involved in formulating complex Boolean strings and expressions, and reviewed six of the more innovative alternative solutions. Each of these offers its own unique perspective on how to solve such problems, and their pioneering efforts provide us with a rich set of design insights and principles. In this brief post, we reflect on the shortcomings of the Boolean string itself, and ask ourselves how we might do better.
A legacy format
There are many professions whose work involves finding answers to complex search challenges. In many cases, the default solution is to use Boolean strings (i.e. Boolean expressions represented as a string of characters). For example, recruiters commonly use Boolean strings to source candidates, crafting expressions such as the following:
(“business analyst” or “systems analyst” or “system analyst” or “data analyst” or “requirements analyst” or “functional analyst”) and crystal and report* and analy* and data near analy* and not inventory and not retail and not (ecommerce or “e-commerce” or b2b or b2c)
Advocates in the profession (quite rightly) pride themselves on an ability to ’speak Boolean’. Indeed, some even refer to themselves as ‘Boolean black belts’.
But the format itself leaves a lot to be desired.
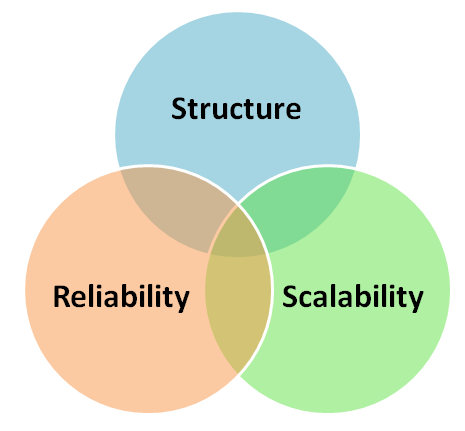
First, it is poor at communicating structure. The use of parentheses as delimiters may be commonplace in programming languages and data structures, but when intended for human interpretation, they are invariably coupled with some sort of physical cue such as indentation. In the absence of such visual signals, parentheses can become lost in a sea of alphanumeric characters, and trying to understand the meaning and structure of such expressions induces unnecessary cognitive load.
Second, it doesn’t scale well. As you add terms to a Boolean string, it grows monotonically in length. This may be acceptable for a handful of terms, but as soon as that grows to double figures and beyond, transparency becomes progressively degraded. A common solution to an analogous problem in software engineering is to offer some form of abstraction, so that lower-level details can be progressively hidden and the overall structure revealed. But Boolean strings (in their native form) offer no such facility.
Third, they are very error-prone. How many times have you revised a problematic Boolean string only to find that a missing bracket was the culprit? Or worse still, you find you had the right number of brackets, but in the wrong place, completely changing the semantics of your search?
Each of the above reasons should provide sufficient motivation to pursue an alternative. Taken together, they provide compelling evidence that a change may be due. Moreover, I’d conjecture that most Boolean strings of any complexity are read many more times than they are written. And in that context, we can and should do more to ensure that the effort invested in them is better realized, and that their content can be better understood, optimised and re-used.
In summary
In this brief post we’ve reviewed some of the shortcomings of using Boolean strings to solve complex search problems. In our next post, we’ll review how we have attempted to apply some of the lessons learned in our own work. In advance of that, if you‘d like to try for yourself, head on over to 2Dsearch, and let us know what you think.